Y Poirot -no, mejor la vieja miss Marple, que contrasta más con los personajes- trata de identificar entre ellos al responsable de un crimen. Pero todos tienen sus motivos, sus historias, sus razones, sus coartadas -y todas se desarman convenientemente: podría decirse que ninguno tiene coartada-. Tan diferentes pero tan iguales a la vez, cuesta distinguir entre ellos al asesino. Ni siquiera se sabe si son cómplices o rivales.
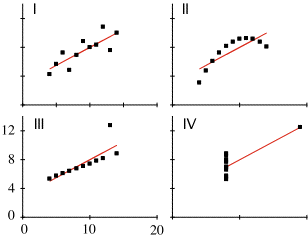
Los gráficos de arriba (tomados de aquí, que a su vez lo sacó de acá) corresponden a cuatro conjuntos de datos, conocidos como el Anscombe's quartet. Coinciden distintos parámetros estadísticos, se "ve" numéricamente que tienen la misma recta de cuadrados mínimos, aunque también se ve claramente en los gráficos que los datos son muy distintos.
No conocía el problema, me lo envía Osvaldo Gonzalez, y es algo así como la pesadilla de su área (data mining, inteligencia artificial). No alcanza con un programa que haga las cuentas y calcule promedios, varianzas, regresiones, errores... para distinguir entre distintos conjuntos de datos. Hace falta mirarlos, o programar algo que mire por uno.
Sospecho que merece mayor difusión (todavía no tiene página en la wikipedia, google da apenas 600 resultados), no sólo por el problema concreto del área, sino como advertencia para ciertos reduccionistas (las famosas power law de las que ya hemos hablado, este artículo que me pasara Weo hace tiempo, etc.).
4 comentarios:
Por casualidad yo tuve que programar "algo" para lidiar con el caso 3 tambien llamado "typo" o "falsa muestra".
En mi caso era un LS multivariable pero el concepto es el mismo:
Descarto el 10% de las muestras que mas lejos estan de la recta "corriente" en el momento de introducir la muestra. Cada vez que entra una muestra nueva, descarto una. Las primeras 10 muestras las valida un humano.
Yo use esto para un modelo de prediccion continua de temperatura en un horno de acero.
es un problema manejar esos datos. ¿son espurios? ¿son reales?
al llegar a esa etapa de decisión uno es consciente de que todo el proceso tuvo un error, sea en el momento en que se cargó el dato (si está mal), o en el momento ese en que se lo descarta (si era real)
Los datos erroneos son errores de medicion (la sonda no llega al acero y por lo tanto da cualquier cosa)
ese ejemplo esta en la pagina 1 de "The visual display of quantitative information" de edward tufte
que hace referencia a:
F.J.Anscombe "Graphs in Statistical Analysis" American Statistician, 27 (Feb 1973), 17-21
Publicar un comentario